このエントリは「TensorFlow Advent Calendar」の12日目の記事です。
これまで僕は、モデルの訓練には「GeForce GTX960」を積んだデスクトップマシンを使ってきました。
この「GeForce GTX960」は、GPUだけあってちゃんと使えばCPUより格段に速いのですが、最高の性能というわけではありません。
機械学習に取り組む中で、科学技術計算などを行う汎用目的(General Purpose)GPUや、複数のGPUで計算を並列化する「マルチGPU」に憧れがないと言えば嘘になります。
しかし、GPUの1枚の価格や電気代、排熱の処理を考えると現実的でないと言う結論に落ち着いていました。
今回、さくらインターネットの高火力コンピューティングが試用できたので、やってみたことをまとめます。
本レポートは、10月5日から12日までの「高火力コンピューティング」試用期間中の取り組みを元にしています。
記事の内容が現在の状況(初期状態)とは異なる場合があります。あらかじめご了承ください。
使用したTensorFlowのバージョンは0.10です。
また、本エントリに掲載しているのコードは、拙著「TensorFlowはじめました」の増補改訂版の第4章の内容に準拠しています。
コードの全体については、下記URLからダウンロードできます。
サンプルコード – train_vgg_adam_minibatch_distort_multi_gpus.py
利用開始
利用開始日の朝、トライアル用のアカウントの認証情報(「アカウント名」と「パスワード」)が送られてきました。
指定されたURLを開いて認証情報を入力すると、専用サーバーのコントロールパネルが表示されます。
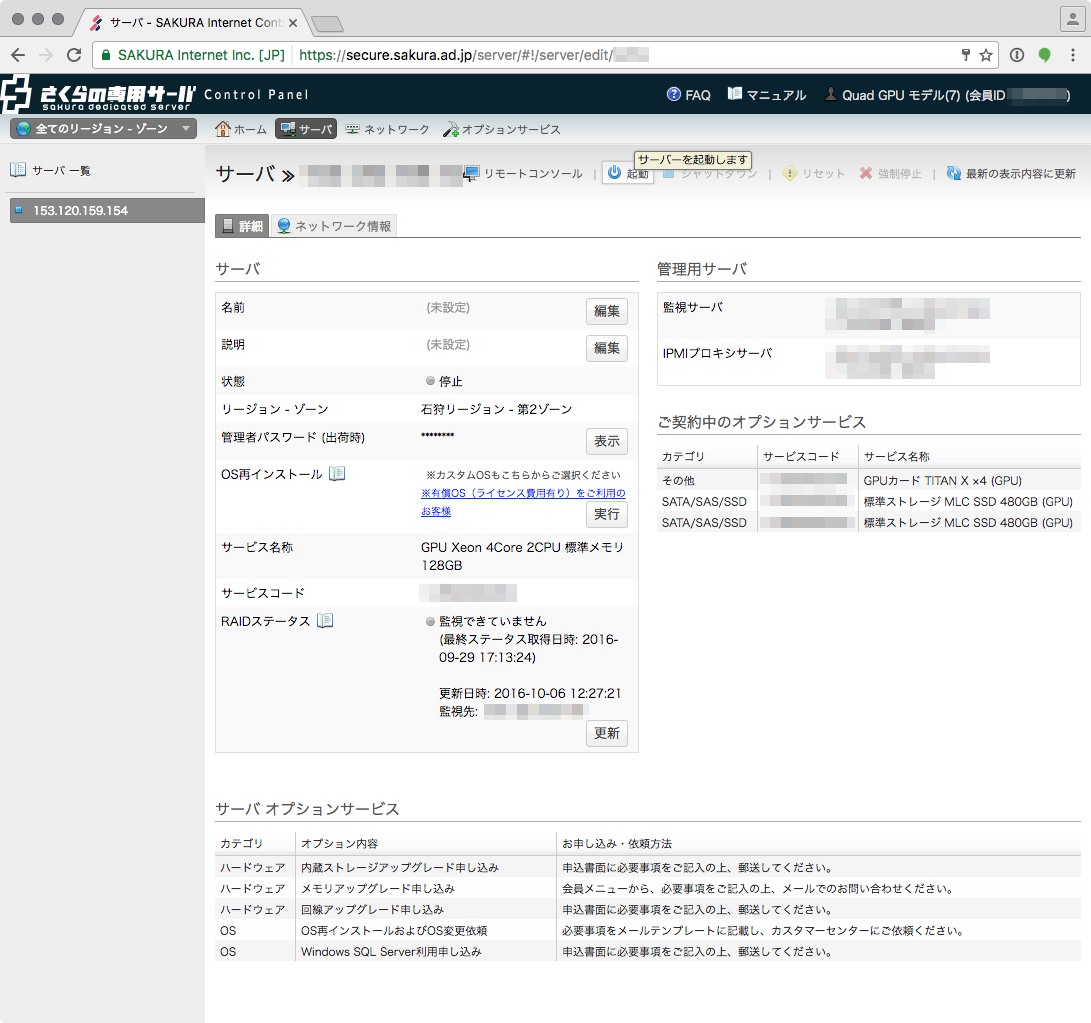
「TITANx4」の文字が頼もしいですね。
ストレージに480GBのSSDが2基搭載されているので、巨大なデータセットにも十分に対応できそうです。
初期OSとして「Ubuntu 14.04 (64bit)」がインストールされていました。
認証情報を通知するメールには「GPUドライバはインストールされていません」とあったのですが、僕の場合は最初からGPUが使える状態になっていました。
Pythonといくつかのパッケージ、CUDA(7.5)とCuDNN(5.1)、TensorFlow(0.10.0)をインストールすれば準備は完了です。
学習(CIFAR-10)
準備ができたので、さっそく学習をしてみます(train_vgg_adam_minibatch_distort_multi_gpus.py)。
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcudnn.so locally
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcurand.so locally
I tensorflow/core/common_runtime/gpu/gpu_device.cc:951] Found device 0 with properties:
name: GeForce GTX TITAN X
major: 5 minor: 2 memoryClockRate (GHz) 1.076
pciBusID 0000:02:00.0
Total memory: 11.93GiB
Free memory: 11.82GiB
W tensorflow/stream_executor/cuda/cuda_driver.cc:572] creating context when one is currently active; existing: 0x2c37dd0
I tensorflow/core/common_runtime/gpu/gpu_device.cc:951] Found device 1 with properties:
name: GeForce GTX TITAN X
major: 5 minor: 2 memoryClockRate (GHz) 1.076
pciBusID 0000:03:00.0
Total memory: 11.93GiB
Free memory: 11.82GiB
W tensorflow/stream_executor/cuda/cuda_driver.cc:572] creating context when one is currently active; existing: 0x30c0ac0
I tensorflow/core/common_runtime/gpu/gpu_device.cc:951] Found device 2 with properties:
name: GeForce GTX TITAN X
major: 5 minor: 2 memoryClockRate (GHz) 1.076
pciBusID 0000:83:00.0
Total memory: 11.93GiB
Free memory: 11.82GiB
W tensorflow/stream_executor/cuda/cuda_driver.cc:572] creating context when one is currently active; existing: 0x354d740
I tensorflow/core/common_runtime/gpu/gpu_device.cc:951] Found device 3 with properties:
name: GeForce GTX TITAN X
major: 5 minor: 2 memoryClockRate (GHz) 1.076
pciBusID 0000:84:00.0
Total memory: 11.93GiB
Free memory: 11.82GiB
使ってみると確かに速いのですが、期待したほどではないという感じでした。
step 0, loss = 4.67 (4.9 examples/sec; 26.282 sec/batch)
step 10, loss = 4.60 (768.2 examples/sec; 0.167 sec/batch)
step 20, loss = 4.65 (745.9 examples/sec; 0.172 sec/batch)
step 30, loss = 4.69 (730.8 examples/sec; 0.175 sec/batch)
step 40, loss = 4.28 (764.6 examples/sec; 0.167 sec/batch)
step 50, loss = 4.33 (779.0 examples/sec; 0.164 sec/batch)
きちんとしているつもりで実はGPUが働いていなかったということは前にもあったので、nvidia-smiコマンドで確認してみます。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 361.93.02 Driver Version: 361.93.02 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX TIT... On | 0000:02:00.0 Off | N/A |
| 22% 34C P2 77W / 250W | 11703MiB / 12212MiB | 29% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX TIT... On | 0000:03:00.0 Off | N/A |
| 22% 29C P8 15W / 250W | 11609MiB / 12212MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX TIT... On | 0000:83:00.0 Off | N/A |
| 22% 28C P8 15W / 250W | 11609MiB / 12212MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX TIT... On | 0000:84:00.0 Off | N/A |
| 22% 30C P8 15W / 250W | 11607MiB / 12212MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
ごらんの通り、GPUが一つしか動作していません。
TensorFlowで複数のGPUを使うには、コード側を変更する必要があります。
マルチGPUへの対応
オリジナルのCIFAR-10チュートリアルのcifar10_multi_gpu_train.pyを参考に、マルチGPUで動作するようにコードを変更します。
勾配の計算
tf.deviceでそれぞれオペレーションを実行するデバイスを指定します。
サンプルでは引数--num_gpusに指定した数のGPU上で、それぞれ勾配(gradients)の計算を行っています。
また、それぞれのグラフの名前が重複しないように、tf.name_scopeで名前空間を区切っています。
opt = tf.train.AdamOptimizer(learning_rate=FLAGS.learning_rate)
reader = Cifar10Reader(filenames)
record = reader.read()
distorted_image = _distort(record.byte_array)
whiten_image = tf.image.per_image_whitening(distorted_image)
batch_image, batch_label = tf.train.batch(
[whiten_image, record.label],
FLAGS.batch_size,
num_threads=6)
tf.image_summary('images', batch_image)
batch_label = tf.reshape(batch_label, [FLAGS.batch_size], 'batch_label')
tower_grads = []
for i in range(FLAGS.num_gpus):
with tf.device('/gpu:%d' % i):
with tf.name_scope('%s_%d' % (TOWER_NAME, i)) as scope:
logits = model.inference(batch_image,
keepprob_placeholder, batch_size=FLAGS.batch_size)
loss = _loss(logits, batch_label)
tf.add_to_collection(KEY_LOSSES, loss)
tf.get_variable_scope().reuse_variables()
losses = tf.get_collection(KEY_LOSSES, scope)
# nameを指定しないと'cross_entropy'と名前が重複してエラーになる
total_loss = tf.add_n(losses, name='total_loss')
grads = opt.compute_gradients(total_loss)
tower_grads.append(grads)
この段階では実際の計算は行われていません。
tower_gradsには、それぞれのGPU(tower)の計算オペレーションが格納されています。
学習(訓練)
最後に、勾配を使って学習を行います。
avg_grads = _average_gradients(tower_grads)
train_op = opt.apply_gradients(avg_grads, global_step=global_step, name='train')
ご覧の通り、それぞれのGPUで計算した勾配を_average_gradients関数に与えています。
マルチGPUに対応しないコードでは、求めた勾配をそのまま学習に使っていました。
def _train(total_loss, global_step):
opt = tf.train.AdamOptimizer(learning_rate=FLAGS.learning_rate)
grads = opt.compute_gradients(total_loss)
train_op = opt.apply_gradients(grads, global_step=global_step)
return train_op
これの「勾配を求めて」「学習する」のステップはopt.minimize(total_loss, global_step=global_step)に置き換えることができます。
しかし、マルチGPUの場合、勾配を求める処理がそれぞれのGPUで行われるので、学習前に平均値を計算します。
_average_gradientsは、勾配の平均を計算する計算グラフを追加する関数です。
def _average_gradients(tower_grads):
average_grads = []
for grad_and_vars in zip(*tower_grads):
grads = []
for g, _ in grad_and_vars:
expanded_g = tf.expand_dims(g, 0)
grads.append(expanded_g)
grad = tf.concat(0, grads)
grad = tf.reduce_mean(grad, 0)
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
実行
マルチGPUに対応したコードを実行すると、次のようになります。
step 0, loss = 4.68 (17.1 examples/sec; 7.467 sec/batch)
step 10, loss = 4.62 (2682.6 examples/sec; 0.048 sec/batch)
step 20, loss = 4.46 (2475.5 examples/sec; 0.052 sec/batch)
step 30, loss = 4.34 (2452.7 examples/sec; 0.052 sec/batch)
step 40, loss = 4.36 (2500.2 examples/sec; 0.051 sec/batch)
step 50, loss = 4.22 (2853.9 examples/sec; 0.045 sec/batch)
処理速度は、単純に約4倍になりました。
nvidia-smiを実行すると、すべてのGPUが動作しているのがわかります。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 361.93.02 Driver Version: 361.93.02 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX TIT... On | 0000:02:00.0 Off | N/A |
| 22% 39C P2 78W / 250W | 11703MiB / 12212MiB | 23% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX TIT... On | 0000:03:00.0 Off | N/A |
| 22% 38C P2 77W / 250W | 11703MiB / 12212MiB | 14% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX TIT... On | 0000:83:00.0 Off | N/A |
| 22% 37C P2 77W / 250W | 11703MiB / 12212MiB | 17% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX TIT... On | 0000:84:00.0 Off | N/A |
| 22% 39C P2 75W / 250W | 11701MiB / 12212MiB | 8% Default |
+-------------------------------+----------------------+----------------------+
すべてのGPUが動作しているのですが、少しばらつきがあります。
特に0番目のGPUの利用率が高く、他のGPUの利用率が低い気がします。
インプット・パイプラインをGPU側に移動
前の変更では、データの読み込み(Cifar10Reader)とミニバッチにまとめる処理(tf.train.batch)についてはGPUを指定しませんでした。
データの読み込み処理などの「インプットパイプライン」は、0番目のGPUでのみ実行されていて、そのため負荷にばらつきが出ていると考えました。
そこでインプットパイプラインも、それぞれのGPUで実行するように変更しました。
opt = tf.train.AdamOptimizer(learning_rate=FLAGS.learning_rate)
tower_grads = []
for i in range(FLAGS.num_gpus):
with tf.device('/gpu:%d' % i):
with tf.name_scope('%s_%d' % (TOWER_NAME, i)) as scope:
reader = Cifar10Reader(filenames)
record = reader.read()
distorted_image = _distort(record.byte_array)
whiten_image = tf.image.per_image_whitening(distorted_image)
batch_image, batch_label = tf.train.batch(
[whiten_image, record.label],
FLAGS.batch_size,
num_threads=6)
tf.image_summary('images', batch_image)
batch_label = tf.reshape(batch_label, [FLAGS.batch_size], 'batch_label')
logits = model.inference(batch_image,
keepprob_placeholder, batch_size=FLAGS.batch_size)
loss = _loss(logits, batch_label)
tf.add_to_collection(KEY_LOSSES, loss)
tf.get_variable_scope().reuse_variables()
losses = tf.get_collection(KEY_LOSSES, scope)
# nameを指定しないと'cross_entropy'と名前が重複してエラーになる
total_loss = tf.add_n(losses, name='total_loss')
grads = opt.compute_gradients(total_loss)
tower_grads.append(grads)
実行
変更後のコードを実行した結果、nvidia-smiの結果は次のようになりました。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 361.93.02 Driver Version: 361.93.02 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX TIT... On | 0000:02:00.0 Off | N/A |
| 22% 51C P2 86W / 250W | 11703MiB / 12212MiB | 37% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX TIT... On | 0000:03:00.0 Off | N/A |
| 22% 48C P2 81W / 250W | 11703MiB / 12212MiB | 26% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX TIT... On | 0000:83:00.0 Off | N/A |
| 22% 47C P2 80W / 250W | 11703MiB / 12212MiB | 27% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX TIT... On | 0000:84:00.0 Off | N/A |
| 22% 48C P2 78W / 250W | 11701MiB / 12212MiB | 34% Default |
+-------------------------------+----------------------+----------------------+
それぞれのGPUの負荷のばらつきは抑えられ、それに伴ってサンプルの処理速度も上がりました。
しかし、GPUの利用率100%には到達しませんでした。
試しにバッチサイズを、それまでの64から128に変更しても、あまり大きな変化はありませんでした。
これは題材になっているCIFAR-10の画像サイズが32×32と比較的小さく「TITAN X」の処理能力を最大限引き出すほどの負荷を与えられなかったためと考えています。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 361.93.02 Driver Version: 361.93.02 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX TIT... On | 0000:02:00.0 Off | N/A |
| 22% 49C P2 78W / 250W | 11703MiB / 12212MiB | 38% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX TIT... On | 0000:03:00.0 Off | N/A |
| 22% 49C P2 76W / 250W | 11703MiB / 12212MiB | 34% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX TIT... On | 0000:83:00.0 Off | N/A |
| 22% 47C P2 75W / 250W | 11703MiB / 12212MiB | 31% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX TIT... On | 0000:84:00.0 Off | N/A |
| 22% 48C P2 74W / 250W | 11701MiB / 12212MiB | 34% Default |
+-------------------------------+----------------------+----------------------+
終わりに
いかがだったでしょうか。
さくらインターネットの高火力コンピューティング、凄さの片鱗こそ見えたものの、僕の力不足で火力を上げることができないまま、試用期間が終わってしまいました。
ちなみに今は、192×192のイラスト画像から顔領域を示すマスク画像を生成するというモデルを訓練しているのですが、
192×192のサンプルを処理するモデルを僕の使っている「GeForce GTX960」のメモリ(2GB)に納めるのに苦労しています。

バッチサイズを減らしたりモデルの軽量化を頑張ってようやくメモリに収まっても1ステップにかかる学習の負荷が大きく、学習は遅々として進みません。
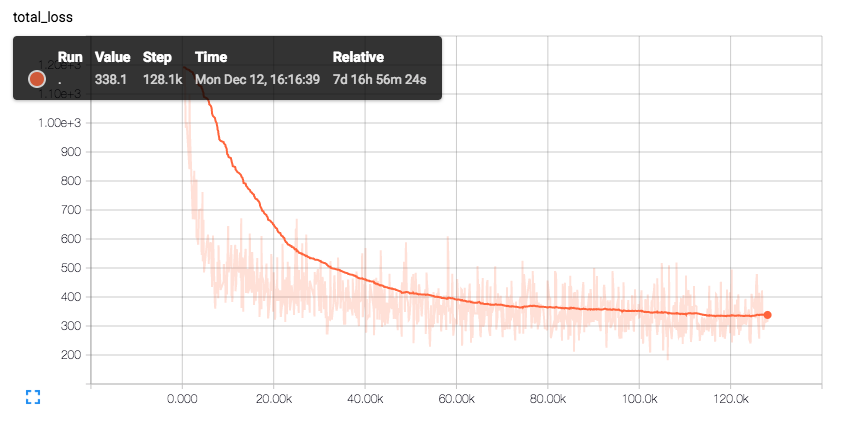
かれこれ1週間ほど処理を続けていますが……高火力が必要なのは、まさに今なんですよ!
「TensorFlow Advent Calendar」13日目の担当はkatsugenerationさんです。
katsugenerationさん、よろしくお願いします。