僕はいま、Google I/O 2016参加で渡米するにあたり、時差ボケ予防のために徹夜でこの記事を書いています。
概要(忙しい人向け)
TensorFlowのチュートリアルにある課題(エクササイズ)に挑戦した。Softmaxの適用については比較的簡単だったが、Fully connected層をLocally connected層に変える課題については難航し、解決していない。
Locally connected層は、重み共有をしない畳み込み層である(cuda-convnet)。
そこで、チュートリアルのモデルのFully connected層をConvolution層に置き換えたところ、学習が正常に行われなくなった。
TensorBoardを通じてモデルの状態を確認したところ、conv2層で勾配消失が起きていることがわかった。さらに調査を続けると、conv2層のweightsの初期値がcuda-convnetに記載されている値と異なっており、修正することで正常に学習できるようになった(数値の食い違いが意図的なものかは不明だが、修正をPull Requestしている)。
「重み共有(Shared weights/Tied weights)」をしないというLocally connectedの条件をTensorFlowでどのように実現するかは現時点でわかっていない。depthwise_conv2dについて検討したが、上手くいかないと判断している(出力フィルタの枚数を減らすことができないため)。
エクササイズについては、今後も調査を続けていく。
TensorFlowのExercise
「TensorFlowは、Tutorialが充実している」と言われます。
僕はTensorFlowから機械学習を始めたので実感はないのですが、僕の周りで他のフレームワークを知っている人の多くは「TensorFlowはチュートリアルが充実している。親切だ」と言っています。
そんなTensorFlowチュートリアルには「エクササイズ」と銘が打たれた「課題」があります。
世の中ディープラーニング全盛。TensorFlowもかなりの人気の中、検索すると「TensorFlowをインストールしてみた」「チュートリアルをやってみた」そんなブログ記事はよく見るのですが、「エクササイズをやってみた」と言うウェブサイトや記事は見あたりませんでした。
もしかするとTensorFlowのサイトのどこをみてもエクササイズの回答が示されていないので、挑戦しても正解か答え合わせができず、「不正確な情報は出せない」と公開していないのかもしれません。
それか、『あまりにも簡単にできてしまったので、みんなわかるだろう』と、公開する必要がないと思っている。そういう人も居るのかもしれません。
ここに居ます。
エクササイズがわからずに苦労している人間が。
僕と同じような人も居るかもしれないので、ここに挑戦の記録を残します。まだ未解決の部分もあるので、わかる人は是非教えてください。
挑戦したエクササイズは「チュートリアル」の畳み込みニューラルネットワークの構築にあります。
チュートリアルの題材は「CIFAR-10」です。
CIFAR-10
CIFAR-10(しーふぁー・てん)は、機械学習において一般物体認識(多クラス分類)のベンチマークとして用いられています。
「airplane」「automobile」「bird」「cat」「deer」「dog」「frog」「horse」「ship」「truck」の10種類の物体が写った小さな画像(32×32ピクセル・RGBカラー)を、訓練データ50,000枚で学習し、テストデータ10,000枚を使って学習速度や正答率を見ます。
エクササイズ Softmax
エクササイズの一つ目は、推論によって導かれるlogitsを「softmax」によって正規化するというものです。
EXERCISE: The output of inference are un-normalized logits.
Try editing the network architecture to return normalized predictions using tf.nn.softmax().
こちらはさほど難しくはありません。出力層で処理した結果をsoftmax_linerに代入する前に、tf.nn.softmaxを挟むだけです。
# softmax, i.e. softmax(WX + b)
with tf.variable_scope('softmax_linear') as scope:
weights = _variable_with_weight_decay('weights', [192, NUM_CLASSES],
stddev=1/192.0, wd=0.0)
biases = _variable_on_cpu('biases', [NUM_CLASSES],
tf.constant_initializer(0.0))
softmax_linear = tf.nn.softmax(tf.add(tf.matmul(local4, weights), biases), name=scope.name)
_activation_summary(softmax_linear)
しかし、前述の通り回答が公式のどこにも見つからないので、こんな単純なことですら、本当に正解かわからないというのが辛いところです……。
(WIP)エクササイズ cuda-convnet
EXERCISE: The model architecture in inference() differs slightly from the CIFAR-10
model specified in cuda-convnet. In particular, the top layers of Alex's original model
are locally connected and not fully connected. Try editing the architecture to exactly
reproduce the locally connected architecture in the top layer.
二つ目はかなり悩みました。
「local3とlocal4の各層をcuda-convnetに示されている実装に合わせる(Fully-connected層からLocally-connected層にする)」というものですが、一部については理解ができたものの、いまだ解決していない部分があります。
Locally Connected Layerとは
まず「Locally connected」の意味がわかりません。これについては4月13日の「TensorFlow勉強会(3)」でも触れた通りです。
そもそもこの二つの層のtf.variable_scopeがlocal3とlocal4になっているじゃないか。なんでこれが「Fully Connected」なのか。4月時点の僕は本気でそう考えていました。
今ならわかります。前の層からの入力を1次元にしたものにweightsをmatmulしているのだから、これはどう見ても全結合です。本当ににありがとうございました。
さて、local3とlocal4の2層が全結合層であることはわかりました。次はこれをLocally Connectedに置き換える必要があります。
最初の疑問「Locally connectedとはどういう意味なのか」に戻ります。
その答えは、エクササイズからリンクされているcuda-convnetの「レイヤー定義」にありました。
[local3]
type=local
inputs=pool2
filters=64
padding=1
stride=1
filterSize=3
channels=64
neuron=relu
initW=0.04
[local4]
type=local
inputs=local3
filters=32
padding=1
stride=1
filterSize=3
channels=64
neuron=relu
initW=0.04
層のtypeがlocalになっていますね。ちなみにcuda-convnetでは畳み込み層はconv、全結合層の場合はfcを指定するようです。たったこれだけで各層の定義ができるのか。TensorFlowよりよっぽど楽じゃないかと驚いたのですが、それは置いておくとして。
typeにlocalが指定されていることはわかりました。しかし、localが具体的にどういう意味になるのかがわかりません。同じサイトの「LayerParams」を見ると、もう少し具体的に記載があります。
Locally-connected layer with unshared weights
This kind of layer is just like a convolutional layer, but without any weight-sharing.
That is to say, a different set of filters is applied at every (x, y) location in the
input image. Aside from that, it behaves exactly as a convolutional layer.
要約すると「Locally-connected層は、畳み込み層と同じようなものだけど、重みを共有しないよ」と言うことのようです。
畳み込み層に置き換える
「畳み込み層と同じようなものなら、まず畳み込み層として実装してみよう」と思いやってみました。
# local3
with tf.variable_scope('local3') as scope:
kernel = _variable_with_weight_decay('weights', shape=[3, 3, 64, 64],
stddev=0.04, wd=0.04)
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.1, shape=[64]))
bias = tf.nn.bias_add(conv, biases)
local3 = tf.nn.relu(bias, name=scope.name)
_activation_summary(local3)
# local4
with tf.variable_scope('local4') as scope:
kernel = _variable_with_weight_decay('weights', shape=[3, 3, 64, 32],
stddev=0.04, wd=0.04)
conv = tf.nn.conv2d(local3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.1, shape=[32]))
bias = tf.nn.bias_add(conv, biases)
local4 = tf.nn.relu(bias, name=scope.name)
_activation_summary(local4)
# softmax, i.e. softmax(WX + b)
with tf.variable_scope('softmax_linear') as scope:
# Move everything into depth so we can perform a single matrix multiply.
reshape = tf.reshape(local4, [FLAGS.batch_size, -1])
dim = reshape.get_shape()[1].value
weights = _variable_with_weight_decay('weights', [dim, NUM_CLASSES],
stddev=1 / float(NUM_CLASSES), wd=0.0)
biases = _variable_on_cpu('biases', [NUM_CLASSES],
tf.constant_initializer(0.0))
softmax_linear = tf.nn.softmax(tf.nn.bias_add(tf.matmul(reshape, weights), biases), name=scope.name)
_activation_summary(softmax_linear)
return softmax_linear
前のpool2からの出力をlocal3とlocal4で畳み込んで、それを最終的に出力層への入力とします。
フィルターサイズなどのパラメーターはcuda-convnetの「レイヤー定義」に合わせました。
ちなみに「レイヤー定義」の中にはlocal4の次に全結合層fcがありますが、これはそのまま出力outputへ繋げるためのものだと判断し、今回は同じvariable_scopeの中に入れてあります。
実験
このモデルで訓練をしたところ……上手くいきませんでした。
具体的には、訓練中にLoss率が2.3から下がらなくなり、その後、テストデータで検証すると結果が常に0.1になります。
正答率が0.1(10%)ということは、訓練したモデルが常に同じ答え(例えば全部truckと答えるなど)を返している可能性が高く、学習が正常に行われていないということを意味します。
Locally-connectedを畳み込み層として実装するアプローチが間違っていたのか。それともどこかでパラメーターを間違えたのか。この時点ではまったくわからず、途方に暮れてしまいました。
原因 – TensorBoardを使って
学習が上手くいかない原因は、まったく別のところにありました。
TensorBoardのHISTOGRAMSでステップごとのモデルの状態を可視化してみると、1,000ステップを超えた辺りで、Gradients(=勾配)がなくなっていることがわかりました。
そして勾配消失は、変更したlocal3でもlocal4でもなく、畳み込み層conv2で起きていました。
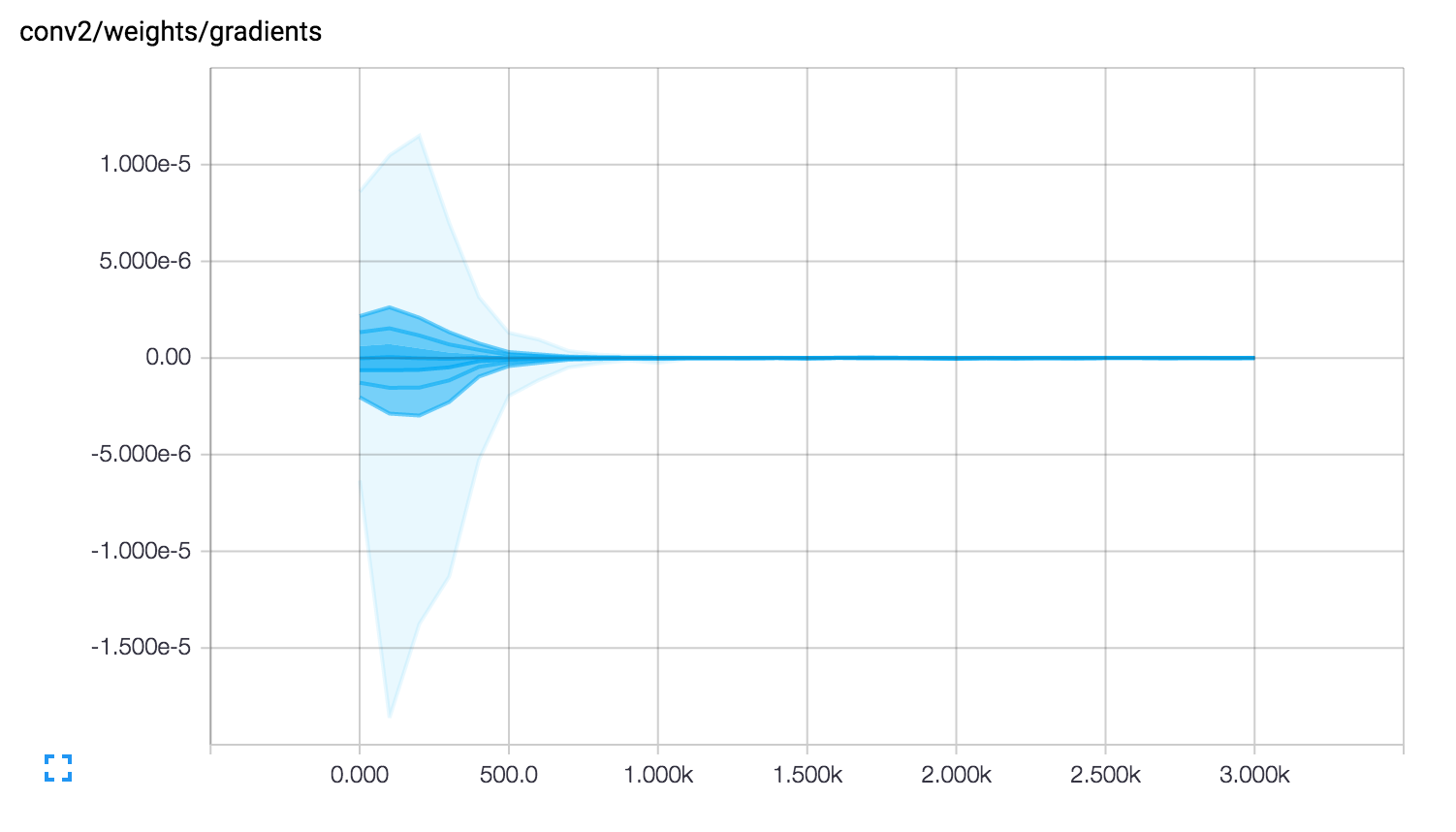
Gradients(勾配)が消失している
直接の原因が「conv2」にあることがわかったので、パラメータを1つずつ、cuda-convnetと比べて確認します。
# conv2
with tf.variable_scope('conv2') as scope:
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 64, 64],
stddev=1e-4, wd=0.0)
conv = tf.nn.conv2d(norm1, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.1))
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope.name)
_activation_summary(conv2)
[conv2]
type=conv
inputs=rnorm1
filters=64
padding=2
stride=1
filterSize=5
channels=64
neuron=relu
initW=0.01
partialSum=8
sharedBiases=1
conv2でweightsを生成するときに指定している初期値(標準偏差stddev)が、cuda-convnetには0.01が指定されているのに対して、チュートリアルのコードでは1e-4 = 0.0001になっています。これでは値が小さすぎるのでしょう。
conv2のstddevに’1e-2’を設定することで、正常に学習が進むようになりました。
pull request
ちなみに1e-4は前の畳み込み層conv1と同じ値なので、書き間違いの可能性があります(エクササイズに挑戦した人を待ち構える罠として意図的に設定された可能性もありますが……)。
TensorFlowはGitHub上で開発されています。せっかくなのでPullRequestを送ってみました。
Match conv2 weights stddev with cuda-convnet’s layer def.
畳み込み層にした変化
local3とlocal4の二層を、Fully connected(全結合)層からConvolutional(畳み込み)層に置き換えることで、それまでは8.5MBあったモデルのサイズが1.4MB程度まで減少しました。これは、全結合層が局所結合の畳み込み層に変わったことでパラメータ数が減少したためと考えられます。
しかし、Fully connected層を2層使ったときのような高速な学習(と正答率)、cuda-convnetで紹介されているほどの性能は得られませんでした。
今後の課題
今回、全結合層を畳み込み層に変えることはできました。しかし、Locally connected層の定義にある「重み共有をしない」について、TensorFlowでどのようにして実現するか現時点でわかっていません。
Locally connected層は”重み共有をしない(unshared weights)畳み込み層である”と理解しています。一つの可能性として、TensorFlowの畳み込みに使う命令をconv2dからdepthwise_conv2dに変更することで、チャンネル別に畳み込み処理をする方法があります。
しかし、depthwise_conv2dの畳み込み処理後のフィルター数は入力フィルター数のn倍となり、前の層からの入力より増加します。フィルター数が64から32に現象するlocal4では利用できません。
別の可能性として、TensorFlowの「畳み込み命令(conv2d)」は、もとより「重み共有(shared weights / tied weights)」をしていないということが考えられるでしょう。その場合「local3」と「local4」については「conv2d」をそのまま用い、それ以前の層「conv1」および「conv2」で重み共有を追加する必要があります。
TensorFlowのエクササイズについては、引き続き調査を続けていきたいと考えています。
技術書典
『機械学習は初心者』と言い続けてそろそろ半年になろうとしている僕が、TensorFlowを題材にした同人誌を出します。
6月25日に秋葉原の通運会館で開かれる技術系同人誌オンリーイベント「技術書典」にて頒布します(今回は有償頒布の予定)。

6/25 技術書典 A-28
技術書典のA-28のブースで僕と握手!